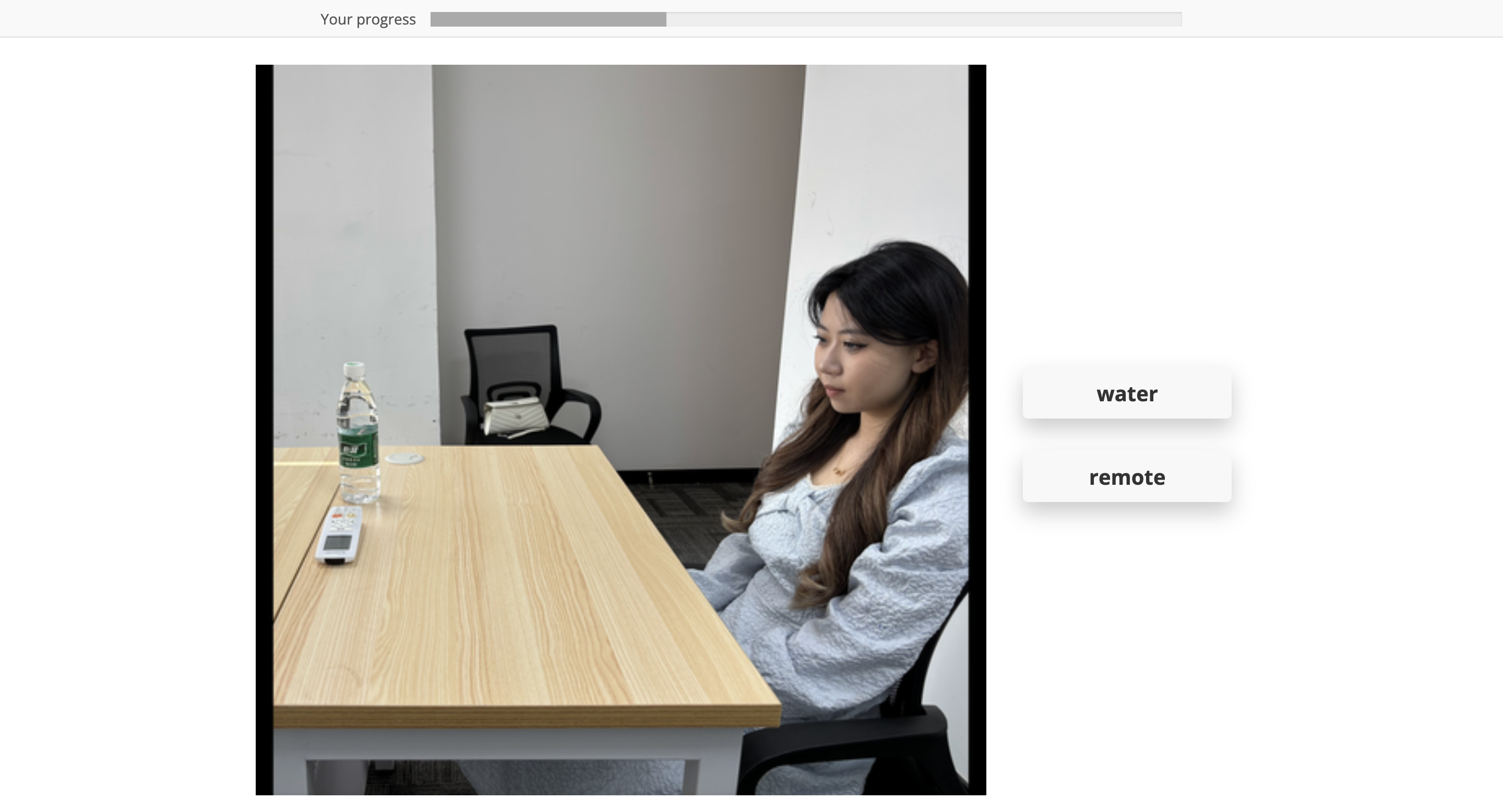
We controlled the gazer's head orientation: sometimes it was directed toward the gaze target, sometimes toward a distractor object, and sometimes left unconstrained.

Other controlled variables. We learned that VLMs are using heuristics that break down when objects are closer or with more objects, but not when it is a side view. Side views are harder for humans but not VLMs because VLMs are mostly using head orientation, still detectable in side views.
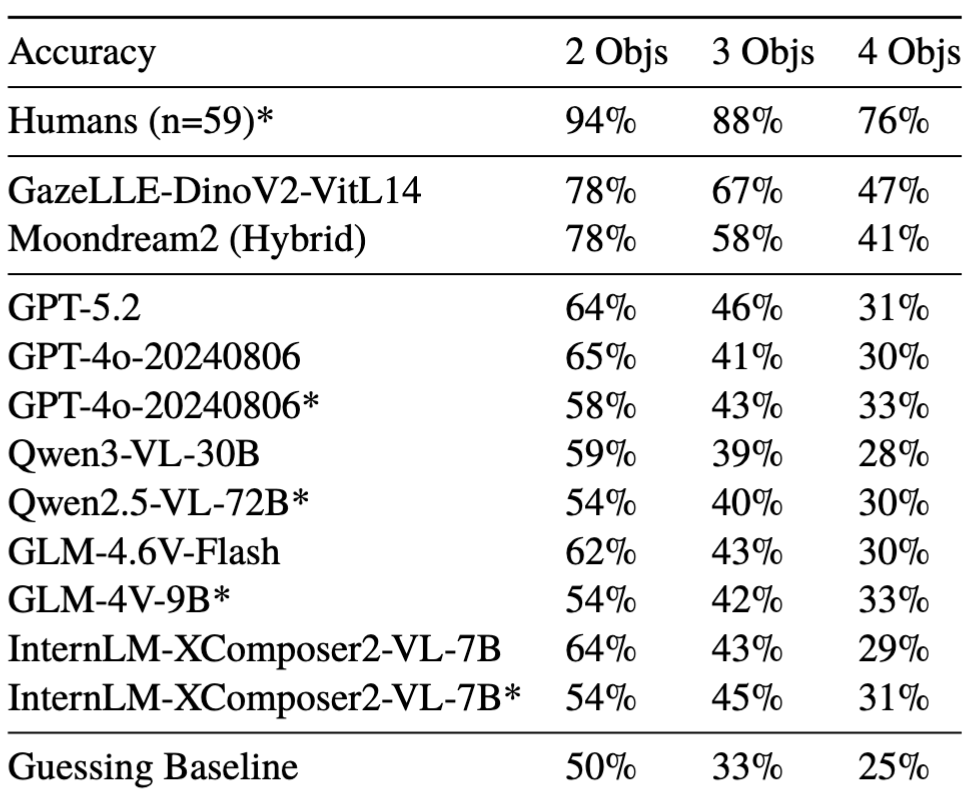
We tested 111 VLMs and 65 humans and found a substantial performance gap: o1 accuracy=50%, human accuracy=89%. Larger or newer VLMs are not better.
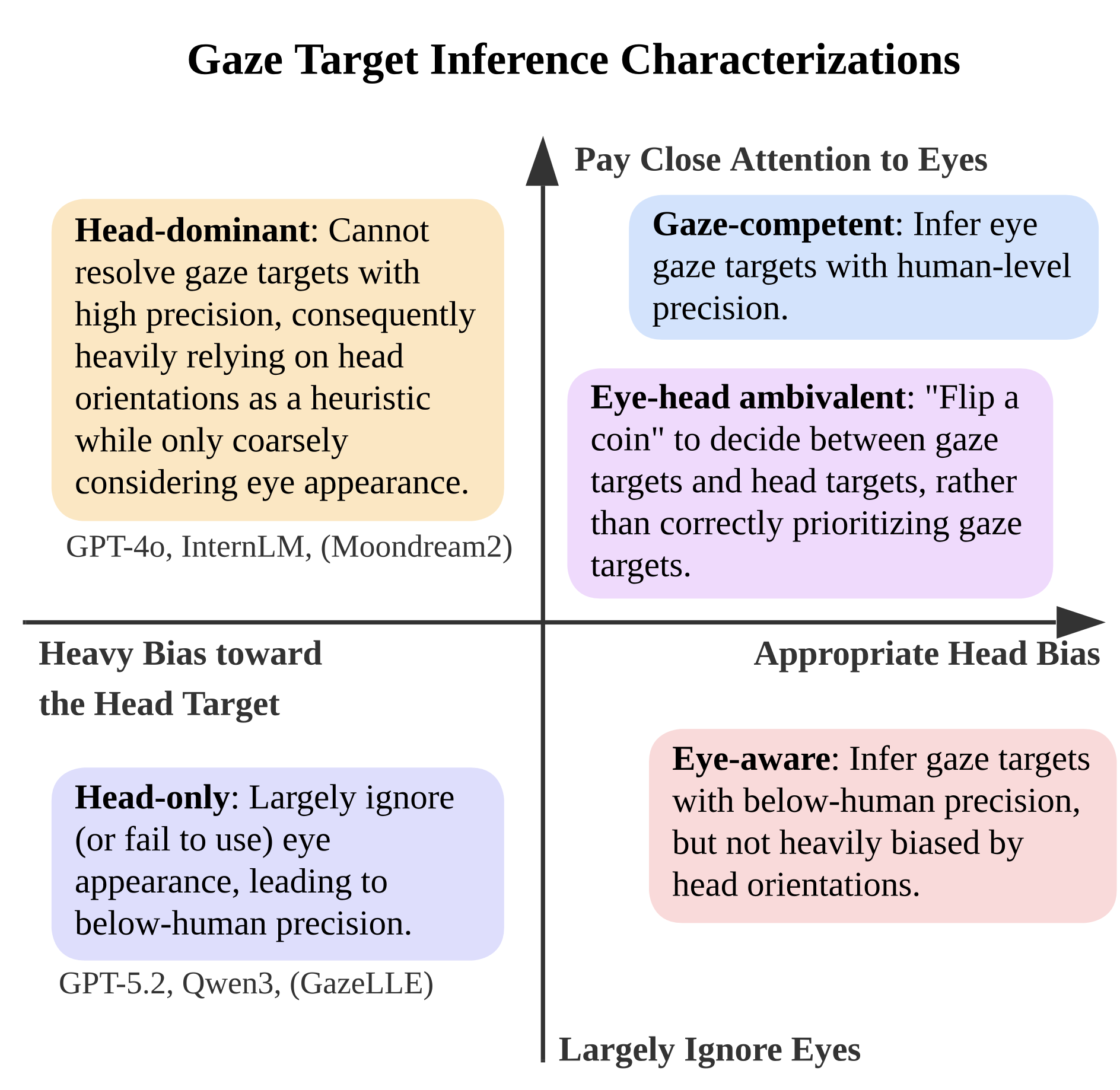
𝐖𝐡𝐲 𝐝𝐢𝐝 𝐭𝐡𝐞𝐲 𝐟𝐚𝐢𝐥? We individually diagnosed 4 strong VLMs (and other baselines). Compared with alternative explanations such as resolution and object-naming skills, the strongest explanatory factor is the head orientation bias.
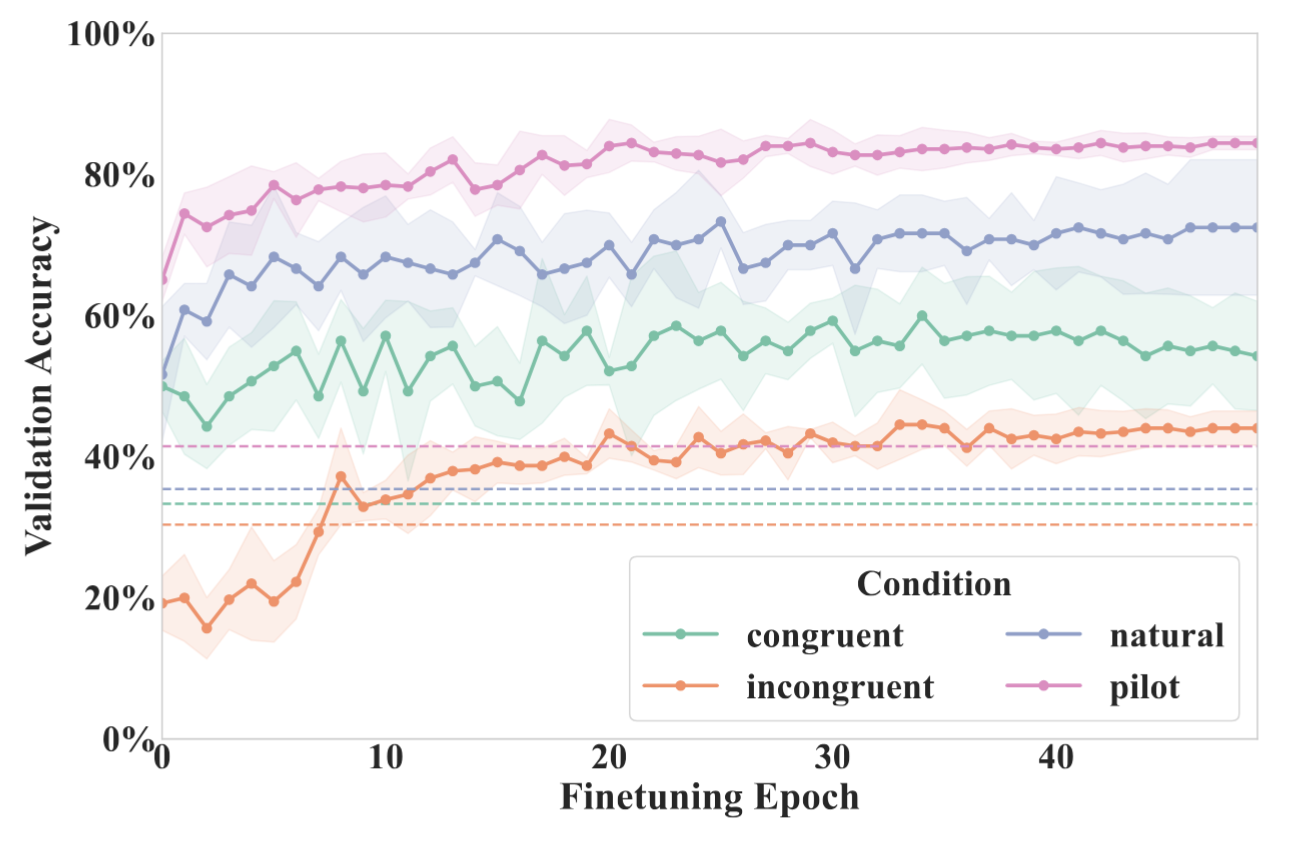
𝐖𝐡𝐲 𝐝𝐨 𝐕𝐋𝐌𝐬 𝐬𝐡𝐨𝐰 𝐡𝐞𝐚𝐝 𝐨𝐫𝐢𝐞𝐧𝐭𝐚𝐭𝐢𝐨𝐧 𝐛𝐢𝐚𝐬? We think it is due to the data, not architecture. Fine-tuning GazeLLE on our stimulus set (where there are more instances requiring fine-grained processing of eye details beyond head orientation) greatly improves its performance in cases where head orientation does not align with gaze direction. It serves as a proof-of-concept experiment showing that head orientation bias can be mitigated. The recommendation is targeted training data where gaze cues must be used to get the correct answer, but not shortcuts like context cue or head/body orientation.